作者:CSDN博客
LangChain英文官方地址:https://www.langchain.com/
LangChain中文官网:https://www.langchain.com.cn/
Python官方地址:https://python.langchain.com/en/latest/
LangChain源代码地址:https://github.com/langchain-ai/langchain
一、LangChain的概念和应用场景
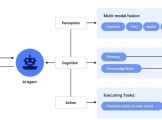
LangChain是一个基于大语言模型的端到端应用程序开发框架,旨在简化和加速利用大型语言模型(LLM)和对话模型构建应用程序的过程。这个框架提供了一套全面的工具、组件和接口,使得开发者能够更轻松地创建和管理复杂的语言模型应用。LangChain 的核心理念是将语言模型的能力与外部数据和计算资源结合起来,以实现更强大的应用功能。
LangChain本质上可被视为类似于开源GPT的插件。它不仅提供了丰富的大型语言模型工具,还支持在开源模型的基础上快速增强模型的功能。通过LangChain,开发人员可以更轻松地管理与语言模型的交互,无缝地连接多个组件,并集成额外的资源,如API和数据库等,以加强应用的能力和灵活性。
LangChain的优势在于为开发人员提供了一个便捷的框架,使其能够更高效地构建应用程序,利用最先进的语言模型和对话系统,同时能够灵活地定制和整合其他必要的资源,为应用程序的开发和部署提供了更大的灵活性和便利性。
Langchain能让机器人不仅仅回答通用问题,还能从你自己的数据库或文件中提取信息,并根据这些信息执行具体操作。
举个例子,如果你想要一个可以帮你总结长篇报告的工具,单用GPT-4可能会因文章太长而无法处理。LangChain提供的工具可以帮你把长篇报告切分成小部分让GPT-4处理,再将结果整合起来,最终生成一个完整的摘要。
另一个例子,假设你想要用GPT-4建一个旅行顾问机器人。单独的GPT-4可能知道很多关于世界各地的信息,但如果不能实时查找最新的航班信息或者酒店价格,它提供的旅行建议可能就不够准确或实用。LangChain就好比是提供了一本指导手册和一套辅助工具,它能让你的旅行顾问机器人链接到航班数据库,记住用户的旅行偏好,甚至根据用户以往的提问历史来提供个性化的建议。。同样地,如果你问:“哪里的垂钓体验最佳?”LangChain可以帮助连接到最新的旅行博客和垂钓爱好者论坛,甚至直接查阅最近的旅行者评论,给你提供最受推荐的目的地。
常见用例
LangChain 目前支持很多用例,有很多场景已经实现了交付,下面是支持的一些常见用例。
自治代理(autonomous agents) : 长时间运行的代理会采取多步操作以尝试完成目标。 AutoGPT 和 BabyAGI就是典型代表。代理模拟(agent simulations) : 将代理置于封闭环境中观察它们如何相互作用,如何对事件作出反应,是观察它们长期记忆能力的有趣方法。个人助理(personal assistants) : 主要的 LangChain 使用用例。个人助理需要采取行动、记住交互并具有您的有关数据的知识。问答(question answering) : 第二个重大的 LangChain 使用用例。仅利用这些文档中的信息来构建答案,回答特定文档中的问题。聊天机器人(chatbots) : 由于语言模型擅长生成文本,因此它们非常适合创建聊天机器人。查询表格数据(tabular) : 如果您想了解如何使用 LLM 查询存储在表格格式中的数据(csv、SQL、数据框等),请阅读此页面。代码理解(code) : 如果您想了解如何使用 LLM 查询来自 GitHub 的源代码,请阅读此页面。与 API 交互(apis) : 使LLM 能够与 API 交互非常强大,以便为它们提供更实时的信息并允许它们采取行动。提取(extraction) : 从文本中提取结构化信息。摘要(summarization) : 将较长的文档汇总为更短、更简洁的信息块。一种数据增强生成的类型。评估(evaluation) : 生成模型是极难用传统度量方法评估的。 一种新的评估方式是使用语言模型本身进行评估。 LangChain 提供一些用于辅助评估的提示/链。
二、LangChain调用本地QWEN7B的量化模型
环境代码:- from langchain_huggingface import HuggingFacePipeline
- from langchain import PromptTemplate, LLMChain
- from transformers import AutoTokenizer, AutoModelForCausalLM
- from transformers import pipeline
- model_path="../../Qwen1.5-1.8B-Chat-GPTQ-Int4"
- model = AutoModelForCausalLM.from_pretrained(
- model_path,
- device_map="auto"
- )
- tokenizer = AutoTokenizer.from_pretrained(model_path)
- pipe = pipeline(
- "text-generation",
- model=model,
- tokenizer=tokenizer,
- max_length=256,
- top_p=1,
- repetition_penalty=1.15
- )
- llama_model = HuggingFacePipeline(pipeline=pipe)
- # template = "给我讲一个关于{content}的{adjective}笑话。"
- #
- # prompt_template = PromptTemplate.from_template(template)
- # template = '''
- # 给我讲一个{product}的笑话。
- # '''
- # prompt = PromptTemplate(
- # input_variables=["product"],
- # template=template
- # )
- # chain = LLMChain(llm=llama_model, prompt=prompt, verbose=True)
- # res=chain.run("能让人笑出声")
- # print(res)
- template = '''
- 你的名字是小黑子,当人问问题的时候,你都会在开头加上'唱,跳,rap,篮球!',然后再回答{question}
- '''
- prompt = PromptTemplate(
- template=template,
- input_variables=["question"] # 这个question就是用户输入的内容,这行代码不可缺少
- )
- chain = LLMChain( # 将llm与prompt联系起来
- llm=llama_model,
- prompt=prompt
- )
- question = '你是谁'
- res = chain.invoke(question) # 运行
- print(res['text']) # 打印结果
1.AutoModelForCausalLM.from_pretrained
是 Hugging Face 的 Transformers 库中的一个类方法,用于从预训练模型中实例化一个因果语言模型。这个方法的主要参数是 `model_name_or_path`,它指定了预训练模型的位置或名称。此外,还有一些可选参数可以进行配置。
device_map:在分布式计算环境中,可以使用 参数将不同的任务分配给不同的计算节点或处理器,并利用并行计算来加速整体计算过程。这里使用 auto 自定选择。
trust_remote_code:默认为 True,表示信任远程代码。如果为 False,则不会从远程存储库加载配置文件。
quantization_config:如果你需要进行量化操作,则需要在这个参数中完成量化配置。
load_in_8bit - 设置为 True 时,预训练模型的权重参数会以更低的精度 [8位] 进行存储,从而减少了模型所需的内存空间。
2.AutoTokenizer.from_pretrained
是 Hugging Face Transformers 库中的一个方法,用于加载预训练的文本处理模(Tokenizer),以便将文本数据转换为模型可以接受的输入格式。这个方法接受多个参数,以下是这些参数的详细说明:
pretrained_model_name_or_path (str):
这是最重要的参数,指定要加载的预训练模型的名称或路径。可以是模型名称(例如 "bert-base-uncased")或模型文件夹的路径。
inputs (additional positional arguments, *optional*)
它表示额外的位置参数,这些参数会传递给标记器(Tokenizer)的__init__()方法。这允许你进一步自定义标记器的初始化。
config ([`PretrainedConfig`], *optional*)
这个配置对象用于确定要实例化的分词器类。
cache_dir (str, optional):
用于缓存模型文件的目录路径
force_download(bool, optional):
如果设置为 `True`,将强制重新下载模型配置,覆盖任何现有的缓存。
resume_download (bool, optional):
这是可选参数,如果设置为 True,则在下载过程中重新开始下载,即使部分文件已经存在。
proxies(`Dict[str, str]`, *optional*)
proxies(可选参数):用于指定代理服务器的设置,是一个字典。代理服务器可以在访问互联网资源时通过中继服务器进行请求,这对于在受限网络环境中使用 Transformers 库来加载模型配置信息非常有用。
proxies = { "http": "http://your_http_proxy_url", "https": "https://your_https_proxy_url" }
revision(str, optional):
指定要加载的模型的 Git 版本。
subfolder(`str`, *optional*)
如果相关文件位于 huggingface.co 模型仓库的子文件夹内(例如 facebook/rag-token-base),请在这里指定。
use_fast (`bool`, *optional*, defaults to `True`)
这是一个布尔值,指示是否强制使用 fast tokenizer,即使其不支持特定模型的功能。默认为 True。
tokenizer_type (`str`, *optional*)
参数用于指定要实例化的分词器的类型。
trust_remote_code(`bool`, *optional*, defaults to `False`)
trust_remote_code=True:
默认情况下,trust_remote_code 设置为 True。当使用 from_pretrained() 方法加载模型配置文件时,它将下载 Hugging Face 模型中心或其他在线资源的配置文件。
trust_remote_code=False:
将 trust_remote_code 设置为 False,则表示不信任从远程下载的配置文件,想要加载本地的配置,需要提供一个本地文件路径,以明确指定要加载的配置文件
总之,trust_remote_code 参数允许您在使用 Hugging Face Transformers 库时控制是否信任从远程下载的配置文件。
3.pipeline
Transformers 库最基础的对象就是 pipeline() 函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。以下是 pipeline 函数的一些常用参数:
- task (str):
这是指定要执行的自然语言处理任务的类型。常见的任务包括:
"sentiment-analysis": 用于情感分析,判断文本的情感倾向。"text-generation": 用于文本生成,例如生成故事或对话。"translation": 用于机器翻译,将一种语言翻译成另一种语言。"summarization": 用于文本摘要,生成文本的简短版本。"fill-mask": 用于填空任务,例如预测句子中缺失的词。"question-answering": 用于问答系统,例如回答用户的问题。"token-classification": 用于标记分类,例如命名实体识别(NER)。"text-classification": 用于文本分类,例如情感分析。
model (str or PreTrainedModel):
这是指定要使用的预训练模型的名称或模型实例。如果未提供,pipeline 将使用默认模型。例如,可以使用 "bert-base-uncased" 或 "gpt2" 等预训练模型。tokenizer (str or PreTrainedTokenizer):
这是指定要使用的分词器的名称或分词器实例。如果未提供,pipeline 将使用与模型匹配的分词器。分词器负责将文本转换为模型可以理解的标记(tokens)。framework (str):
这是指定要使用的深度学习框架。可以是 "pt"(PyTorch)或 "tf"(TensorFlow)。默认情况下,pipeline 会自动检测可用的框架。device (int):
这是指定要使用的设备编号。例如,-1 表示使用 CPU,0 表示使用第一个 GPU。如果系统中有多个 GPU,可以使用 1、2 等表示其他 GPU。binary_output (bool):
对于某些任务(如情感分析),是否返回二进制输出。如果设置为 True,则只返回正/负结果,而不是具体的分数。top_k (int):
对于某些任务(如填空),返回的前 k 个结果。例如,在填空任务中,可以返回最可能的 k 个词。top_p (float):
top_p参数控制生成文本的质量。它表示生成文本中最有可能出现的token的累计概率,如果累计概率超过了top_p,则该token将被视为无效。较高的top_p将导致更准确的预测和更高的质量,而较低的top_p则会导致更多的随机性和更多的错误。max_length (int):
生成文本的最大长度。在文本生成任务中,生成的文本长度不会超过这个值。min_length (int):
生成文本的最小长度。在文本生成任务中,生成的文本长度不会低于这个值。do_sample (bool):
是否使用采样策略生成文本。如果设置为 True,则使用随机采样生成文本,而不是确定性的贪婪解码。num_beams (int):
使用 beam search 时的 beam 数量。Beam search 是一种生成文本的方法,它在每一步保留最有可能的 num_beams 个候选序列。temperature (float):
调整生成文本的随机性。较高的温度值会增加随机性和多样性,较低的温度值会减少随机性。repetition_penalty (float):
控制生成文本中重复词的惩罚。较高的值会减少重复词的出现。length_penalty (float):
控制生成文本的长度惩罚。较高的值会鼓励生成较长的文本,较低的值会鼓励生成较短的文本。
这些参数可以根据具体的任务和需求进行调整,以获得最佳的性能和结果。
4.HuggingFacePipeline
目前只支持`text-generation`, `text2text-generation`, `summarization` 和`translation` 。- ##Example using from_model_id:
-
- from langchain_huggingface import HuggingFacePipeline
- hf = HuggingFacePipeline.from_model_id(
- model_id="gpt2",
- task="text-generation",
- pipeline_kwargs={"max_new_tokens": 10},
- )
- ## Example passing pipeline in directly:
- from langchain_huggingface import HuggingFacePipeline
- from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
- model_id = "gpt2"
- tokenizer = AutoTokenizer.from_pretrained(model_id)
- model = AutoModelForCausalLM.from_pretrained(model_id)
- pipe = pipeline(
- "text-generation", model=model, tokenizer=tokenizer, max_new_tokens=10
- )
- hf = HuggingFacePipeline(pipeline=pipe)
prompt template是指生成提示的可重复的方式。它包含一个文本字符串(“模板”),可以接收来自最终用户的一组参数并生成提示。
下面是一个prompt template的简单例子:- from langchain import PromptTemplate
- template = """\
- 您是新公司的命名顾问。
- 生产{product}的公司起什么好名字?
- """
- prompt = PromptTemplate.from_template(template)
- prompt.format(product="彩色袜子")
- # ->您是新公司的命名顾问。
- 一家生产彩色袜子的公司起什么名字好呢?
该模板支持任意数量的变量,包括无变量:- from langchain.prompts import PromptTemplate
- prompt_template = PromptTemplate.from_template("Tell me a joke")
- prompt_template.format()
例如:- from langchain.prompts import PromptTemplate
- jinja2_template = "Tell me a {{ adjective }} joke about {{ content }}"
- prompt = PromptTemplate.from_template(jinja2_template, template_format="jinja2")
- prompt.format(adjective="funny", content="chickens")
- # Output: Tell me a funny joke about chickens.
PromptTemplate 支持invoke、ainvoke、stream、astream、batch、abatch、astream_log等调用。PromptTemplate 接受一个字典(prompt变量)并返回一个StringPromptValue。value对象可以转换成不同的格式,为后续使用和处理提供了便利。根据StringPromptValue文档可知StringPromptValue类继承自基类PromptValue,表示一个字符串prompt的值,有以下方法:__init__方法:用于根据关键字参数构建一个StringPromptValue实例。需要一个必填的text参数,表示prompt的文本。还有可选的type参数,默认为’StringPromptValue’,表示值的类型。如果输入数据不合法会抛出ValidationError。
copy 方法:复制模型的方法,可以选择包含、排除或更新某些字段。deep=True时为深拷贝。
dict 方法:将模型转换为字典的方法,可以选择包含或排除某些字段。
to_messages 方法:将prompt的值转换为消息列表并返回。
to_string 方法:将prompt的值转换为字符串并返回。- prompt_template = PromptTemplate.from_template(
- "给我讲一个关于{content}的{adjective}笑话。"
- )
- jinja2_template = "Tell me a {{ adjective }} joke about {{ content }}"
- prompt = PromptTemplate.from_template(jinja2_template, template_format="jinja2")
- pmp=prompt_template.format(content="鸡", adjective="幽默")
- print(pmp)
- # 给我讲一个关于鸡的幽默笑话。
- prompt_val = prompt_template.invoke({"adjective": "funny", "content": "chickens"})
- print(prompt_val)
- # text='给我讲一个关于chickens的funny笑话。'
- print(prompt_val.to_string())
- # 给我讲一个关于chickens的funny笑话。
- print(prompt_val.to_messages())
- # [HumanMessage(content='给我讲一个关于chickens的funny笑话。')]
- print(prompt_val.copy())
- # text='给我讲一个关于chickens的funny笑话。'
- print(prompt_val.copy(update={"text": "Hello! How are you?"}))
- # text='Hello! How are you?'
- print(prompt.dict())
- '''
- {"name": null, "input_variables": ["adjective", "content"], "optional_variables": [], "input_types": {},
- "output_parser": null, "partial_variables": {}, "metadata": null, "tags": null,
- "template": "Tell me a {{ adjective }} joke about {{ content }}",
- "template_format": "jinja2", "validate_template": false}
- '''
- print(prompt.json())
- '''
- {"name": null, "input_variables": ["adjective", "content"], "optional_variables": [], "input_types": {},
- "output_parser": null, "partial_variables": {}, "metadata": null, "tags": null,
- "template": "Tell me a {{ adjective }} joke about {{ content }}",
- "template_format": "jinja2", "validate_template": false}
- '''
PromptTemplate会通过检查输入的变量是否与模板中定义的变量相匹配来验证模板字符串。如果存在不匹配的变量,默认情况下会引发ValueError异常。你可以通过设置validate_template=False,禁用这种验证行为,因此不再会引发错误。- #2024年7月17日13:56:14最新版langchain已经不会检查是否匹配,以下都不会报异常
- template = "I am learning langchain because {reason}."
- # ValueError due to extra variables
- prompt_template = PromptTemplate(template=template,
- input_variables=["reason", "foo"],
- validate_template=False)
- print(prompt_template.format(reason="to learn", foo="bar"))
- prompt_template = PromptTemplate(template=template,
- input_variables=["reason", "foo"])
- print(prompt_template.format(reason="to learn", foo="bar"
- '''
- I am learning langchain because to learn.
- I am learning langchain because to learn.
- '''
LangChain提供了一组默认的提示模板,用于生成各种任务的提示。然而,有时默认模板可能无法满足特定需求,例如希望为语言模型创建具有特定动态指令的自定义模板。本节介绍使用PromptTemplate创建自定义提示。
为了创建自定义字符串提示模板,需要满足两个要求:
必须具有 input_variables 属性,指明模板需要什么输入变量;必须定义一个 format 方法,该方法接受与预期 input_variables 相对应的关键字参数,并返回格式化后的提示。
原文地址:https://blog.csdn.net/a2503099087/article/details/140459773 |
























 广告
广告