作者:qyhua
一 什么是RAG?
RAG(Retrieval-Augmented Generation)是一种结合了检索和生成模型的方法,主要用于解决序列到序列的任务,如问答、对话系统、文本摘要等。它的核心思想是通过从大量文档中检索相关信息,然后利用这些信息来增强生成模型的输出。
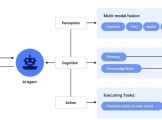
原理如下图:
二 RAG实现思路
RAG实现思路分为准备数据与应用检索两阶段,如图:
阶段一 数据准备阶段
数据提取:对多种格式(如 PDF、Word、Markdown、数据库和 API 等)的数据进行处理,包括过滤、压缩、格式化等,使其成为统一的范式。分块(chunking):将初始文档分割成合适大小的块,在不丢失语义的前提下,尽量保持句子或段落的完整性。可以根据换行、句号、问号、感叹号等进行切分,或以其他合适的原则进行分割。最终将语料分割成 chunk 块,以便在检索时获取相关性最高的 top_n 块。向量化(embedding):使用嵌入模型将文本数据转化为向量矩阵。常用的 embedding 模型有很多,例如 moka-ai/m3e-base、ganymedenil/text2vec-large-chinese 等,也可以参考 huggingface 推出的嵌入模型排行榜。向量的质量会直接影响到后续检索的效果。数据入库:将向量化后的数据构建索引,并写入向量数据库。适用于 RAG 场景的向量数据库包括 facebookresearch/faiss(本地)、chroma、elasticsearch、milvus 等。可以根据业务场景、硬件、性能需求等因素综合考虑,选择合适的数据库。
阶段二 应用阶段:
问题向量化:使用与数据准备阶段相同的嵌入模型,将用户的提问转化为向量。数据检索:通过计算查询向量与向量数据库中存储向量的相似性得分,采用相似性检索的方式从数据库中召回与提问最相关的知识。常见的相似性计算方法包括余弦相似性、欧氏距离、曼哈顿距离等。获取索引数据:获取检索到的相关数据。注入 prompt:将用户查询和检索到的相关知识整合成一个提示模板。prompt 中通常包括任务描述、背景知识(即检索得到的相关内容)、任务指令(一般为用户提问)等。根据任务场景和大模型性能,也可以在 prompt 中适当加入其他指令以优化大模型的输出。LLM 生成答案:将增强后的提示输入到大型语言模型(LLM)中,让模型生成相应的答案。
三 用Python代码实现RAG
使用langchain框架用python代码实现,代码如下:- import os
- import faiss
- from langchain.retrievers import ContextualCompressionRetriever
- from langchain_community.vectorstores import FAISS
- from langchain_core.prompts import PromptTemplate
- from langchain_huggingface import HuggingFaceEmbeddings
- from langchain_community.llms.ollama import Ollama
- from langchain_core.output_parsers import StrOutputParser
- from langchain_core.runnables import RunnablePassthrough
- from langchain_text_splitters import RecursiveCharacterTextSplitter
- import config as cfg
- from log_util import LogUtil
- from auto_directory_loader import AutoDirectoryLoader
- from BCEmbedding.tools.langchain import BCERerank
- doc_path = cfg.load_doc_dir
- # 在线 embedding model
- embedding_model_name = 'maidalun1020/bce-embedding-base_v1'
- model1_path = r'F:\ai\ai_model\maidalun1020_bce_embedding_base_v1'
- model2_path = r'F:\ai\ai_model\maidalun1020_bce_reranker_base_v1'
- # 本地模型路径
- embedding_model_kwargs = {'device': 'cuda:0'}
- embedding_encode_kwargs = {'batch_size': 32, 'normalize_embeddings': True}
- embeddings = HuggingFaceEmbeddings(
- model_name=model1_path,
- model_kwargs=embedding_model_kwargs,
- encode_kwargs=embedding_encode_kwargs
- )
- reranker_args = {'model': model2_path, 'top_n': 5, 'device': 'cuda:0'}
- reranker = BCERerank(**reranker_args)
- # 检查FAISS向量库是否存在
- if os.path.exists(cfg.faiss_index_path):
- # 如果存在,从本地加载
- LogUtil.info("FAISS index exists. Loading from local path...")
- vectorstore = FAISS.load_local(cfg.faiss_index_path, embeddings, allow_dangerous_deserialization=True)
- LogUtil.info("FAISS index exists. Loading from local path...")
- else:
- # 如果不存在,加载txt文件并创建FAISS向量库
- LogUtil.info("FAISS index does not exist. Loading txt file and creating index...")
- loader = AutoDirectoryLoader(doc_path, glob="**/*.txt")
- docs = loader.load()
- LogUtil.info(f"Loaded documents num:{len(docs)}")
- # 从文档创建向量库
- # 文本分割
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=cfg.chunk_size, chunk_overlap=cfg.chunk_overlap)
- documents = text_splitter.split_documents(docs)
- LogUtil.info(f"Text splits num :{len(documents)}", )
- # 创建向量存储
- vectorstore = FAISS.from_documents(documents, embeddings)
- LogUtil.info("create db ok.")
- # 保存向量库到本地
- vectorstore.save_local(cfg.faiss_index_path)
- LogUtil.info("Index saved to local ok.")
- # 将索引搬到 GPU 上
- res = faiss.StandardGpuResources()
- gpu_index = faiss.index_cpu_to_gpu(res, 0, vectorstore.index)
- vectorstore.index = gpu_index
- retriever = vectorstore.as_retriever(search_type="mmr", search_kwargs={"k": 10})
- test_ask="宴桃园豪杰三结义有谁参加了?"
- # 调试查看结果
- retrieved_docs = retriever.invoke(test_ask)
- for doc in retrieved_docs:
- print('++++++单纯向量库提取++++++++')
- print(doc.page_content)
- compression_retriever = ContextualCompressionRetriever(
- base_compressor=reranker, base_retriever=retriever
- )
- response = compression_retriever.get_relevant_documents(test_ask)
- print("============================================compression_retriever")
- print(response)
- print("---------------------end")
- # 定义Prompt模板
- prompt_template = """
- 问题:{question}
- 相关信息:
- {retrieved_documents}
- 请根据以上信息回答问题。
- """
- prompt = PromptTemplate(
- input_variables=["question", "retrieved_documents"],
- template=prompt_template,
- )
- # 创建LLM模型
- llm = Ollama(model="qwen2:7b")
- def format_docs(all_docs):
- txt = "\n\n".join(doc.page_content for doc in all_docs)
- print('+++++++++使用bce_embedding + bce-reranker 上下文内容++++++')
- print(txt)
- return txt
- rag_chain = (
- {"retrieved_documents": compression_retriever | format_docs, "question": RunnablePassthrough()}
- | prompt
- | llm
- | StrOutputParser()
- )
- r = rag_chain.invoke(test_ask)
- print("++++++加 LLM模型处理最终结果++++++++")
- print(r)
第一步,直接向量库检索,相近最近的10条内容如下:

经过 bce-embedding与bce_reranker两在模型的处理,结果也是准确的

再提交给LLM处理后的效果

本地环境:win10系统,本地安装了ollama 并使用的是阿里最新的qwen2:7b,其实qwen:7b测试结果也是准确的。另外还使用了bce-embedding作为嵌入模型,之前测试使用过Lam2+nomic-embed-text做了很多测试发现中文无论怎么调试,都不是很理想,回答的问题总是在胡说八道的感觉。RAG应用个人感觉重点资料输入这块也很重要,像图片里的文字非得要ocr技术,这一点发现有道的qanything做得非常好,以后看来要花点时间查看qanything的源代码好好恶补一下自己这一块。
原文地址:https://blog.csdn.net/qyhua/article/details/140188769 |


























 广告
广告