from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(openai_api_key="YOUR_KEY")
messages =[
SystemMessage(content="你是一个友好的中英翻译助手。"),
HumanMessage(content="I love programming.")]
response = chat(messages)
print(response.content)# 输出翻译后的中文
复制代码
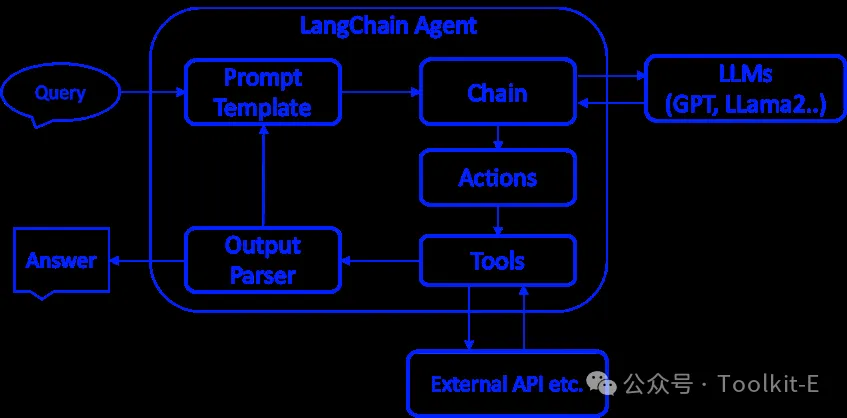
在上述代码中,我们定义了一个系统消息指示角色身份,然后传入用户消息,ChatOpenAI 会返回一个 AI 消息对象,其中包含模型的回复文本。通过聊天模型接口,开发者能够方便地构造多轮对话,处理上下文消息列表等。LangChain 还支持批量对话调用以及流式响应等高级特性,用于提升调用效率和用户体验。
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】